
Взять кредит, оформить визу, да и просто запустить смартфон последней модели — сделать все это сегодня невозможно без участия алгоритмов распознавания лиц. Они помогают полицейским в расследованиях, музыкантам — на сцене, но понемногу превращаются во всевидящее око, следящее за всеми нашими действиями онлайн и офлайн.
Алгоритмы (технологии)
Определить человека по фото с точки зрения компьютера означает две очень разные задачи: во‑первых, найти лицо на снимке (если оно там есть), во‑вторых, вычленить из изображения те особенности, которые отличают этого человека от других людей из базы данных.
1. Найти
Попытки научить компьютер находить лицо на фотографиях проводились еще с начала 1970-х годов. Было испробовано множество подходов, но важнейший прорыв произошел существенно позднее — с созданием в 2001 году Полом Виолой и Майклом Джонсом метода каскадного бустинга, то есть цепочки слабых классификаторов. Хотя сейчас есть и более хитрые алгоритмы, можно поспорить, что и в вашем сотовом телефоне, и в фотоаппарате работает именно старый добрый Виола — Джонс. Все дело в замечательной быстроте и надежности: даже в далеком 2001 году средний компьютер с помощью этого метода мог обрабатывать по 15 снимков в секунду. Сегодня эффективность алгоритма удовлетворяет всем разумным требованиям. Главное, что нужно знать об этом методе, — он устроен удивительно просто. Вы даже не поверите насколько.
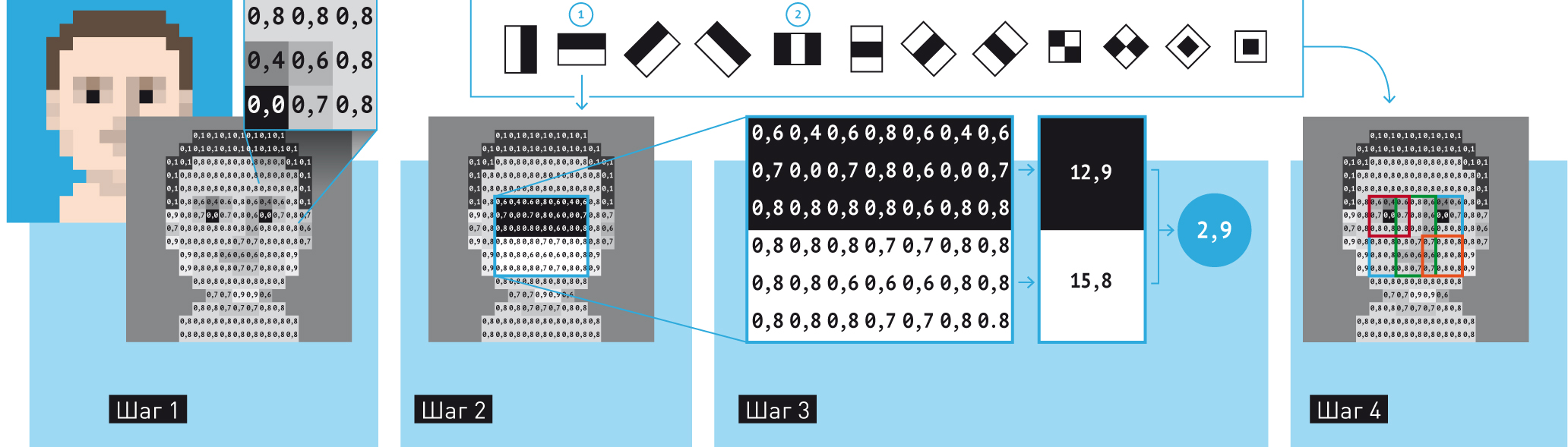
- Шаг1. Убираем цвет и превращаем изображение в матрицу яркости.
- Шаг 2. Накладываем на нее одну из квадратных масок — они называются признаками Хаара. Проходимся с ней по всему изображению, меняя положение и размер.
- Шаг 3. Складываем цифровые значения яркости из тех ячеек матрицы, которые попали под белую часть маски, и вычитаем из них те значения, что попали под черную часть. Если хотя бы в одном из случаев разность белых и черных областей оказалась выше определенного порога, берем эту область изображения в дальнейшую работу. Если нет — забываем про нее, здесь лица нет.
- Шаг 4. Повторяем с шага 2 уже с новой маской — но только в той области изображения, которая прошла первое испытание.
Почему это работает? Посмотрите на признак [1]. Почти на всех фотографиях область глаз всегда немного темнее области непосредственно ниже. Посмотрите на признак [2]: светлая область посередине соответствует переносице, расположенной между темными глазами. На первый взгляд черно-белые маски совсем не похожи на лица, но при всей своей примитивности они имеют высокую обобщающую силу.
Почему так быстро? В описанном алгоритме не отмечен один важный момент. Чтобы вычесть яркость одной части изображения из другой, понадобилось бы складывать яркость каждого пикселя, а их может быть много. Поэтому на самом деле перед наложением маски матрица переводится в интегральное представление: значения в матрице яркости заранее складываются таким образом, чтобы интегральную яркость прямоугольника можно было получить сложением всего четырех чисел.
Как собрать каскад? Хотя каждый этап наложения маски дает очень большую ошибку (реальная точность ненамного превышает 50%), сила алгоритма — в каскадной организации процесса. Это позволяет быстро выкидывать из анализа области, где лица точно нет, и тратить усилия только на те области, которые могут дать результат. Такой принцип сборки слабых классификаторов в последовательности называется бустингом (подробнее о нем можно прочитать в октябрьском номере «ПМ» или здесь). Общий принцип такой: даже большие ошибки, будучи перемножены друг на друга, станут невелики.
2. Упростить
Найти особенности лица, которые позволили бы идентифицировать его владельца, означает свести реальность к формуле. Речь идет об упрощении, причем весьма радикальном. Например, различных комбинаций пикселей даже на миниатюрном фото 64 x 64 пикселя может быть огромное количество — (28)64 x 64 = 232768 штук. При этом для того, чтобы пронумеровать каждого из 7,6 млрд людей на Земле, хватило бы всего 33 бита. Переходя от одной цифры к другой, нужно выкинуть весь посторонний шум, но сохранить важнейшие индивидуальные особенности. Специалисты по статистике, хорошо знакомые с такими задачами, разработали множество инструментов упрощения данных. Например, метод главных компонент, который и заложил основу идентификации лиц. Впрочем, в последнее время сверточные нейросети оставили старые методы далеко позади. Их строение довольно своеобразно, но, по сути, это тоже метод упрощения: его задача — свести конкретное изображение к набору особенностей.

Шаг 1
Накладываем на изображение маску фиксированного размера (правильно она называется ядром свертки), перемножаем яркость каждого пикселя изображения на значения яркости в маске. Находим среднее значение для всех пикселей в «окошке» и записываем его в одну ячейку следующего уровня.

Шаг 2.
Сдвигаем маску на фиксированный шаг, снова перемножаем и снова записываем среднее в карту признаков.

Шаг 3.
Пройдясь по всему изображению с одной маской, повторяем с другой — получаем новую карту признаков.

Шаг 4.
Уменьшаем размер наших карт: берем несколько соседних пикселей (например, квадрат 2×2 или 3×3) и переносим на следующий уровень только одно максимальное значение. То же самое проводим для карт, полученных со всеми другими масками.

Шаг 5, 6.
В целях математической гигиены заменяем все отрицательные значения нулями.
Повторяем с шага 2 столько раз, сколько мы хотим получить слоев в нейросети.

Шаг 7, 8.
Из последней карты признаков собираем не сверточную, а полносвязную нейросеть: превращаем все ячейки последнего уровня в нейроны, которые с определенным весом влияют на нейроны следующего слоя.
Последний шаг. В сетях, обученных классифицировать объекты (отличать на фото кошек от собак и пр.), здесь находится выходной слой, то есть список вероятностей обнаружения того или иного ответа. В случае с лицами вместо конкретного ответа мы получаем короткий набор самых важных особенностей лица. Например, в Google FaceNet это 128 абстрактных числовых параметров.
3. Опознать
Самый последний этап, собственно идентификация, — самый простой и даже тривиальный шаг. Он сводится к тому, чтобы оценить похожесть полученного списка признаков на те, что уже есть в базе данных. На математическом жаргоне это означает найти в пространстве признаков расстояние от данного вектора до ближайшей области известных лиц. Точно так же можно решить и другую задачу — найти похожих друг на друга людей.
Почему это работает? Сверточная нейросеть «заточена» на то, чтобы вытаскивать из изображения самые характерные черты, причем делать это автоматически и на разных уровнях абстракции. Если первые уровни обычно реагируют на простые паттерны вроде штриховки, градиента, четких границ
Откуда берутся маски? В отличие от тех масок, что используются в алгоритме Виолы — Джонса, нейросети обходятся без помощи человека и находят маски в процессе обучения. Для этого нужно иметь большую обучающую выборку, в которой имелись бы снимки самых разных лиц на самом разном фоне. Что касается того результирующего набора особенностей, которые выдает нейросеть, то он формируется по методу троек. Тройки — это наборы изображений, в которых первые два представляют собой фотографию одного и того же человека, а третье — снимок другого. Нейросеть учится находить такие признаки, которые максимально сближают первые изображения между собой и при этом исключают третье.
Чья нейросеть лучше? Идентификация лиц давно уже вышла из академии в большой бизнес. И здесь, как и в любом бизнесе, производители стремятся доказать, что именно их алгоритмы лучше, хотя не всегда приводят данные открытого тестирования. Например, по информации конкурса MegaFace, в настоящее время лучшую точность показывает российский алгоритм deepVo V3 компании «Вокорд» с результатом в 92%. Гугловский FaceNet v8 в этом же конкурсе показывает всего 70%, а DeepFace от Facebook с заявленной точностью в 97% в конкурсе вовсе не участвовал. Интерпретировать такие цифры нужно с осторожностью, но уже сейчас понятно, что лучшие алгоритмы почти достигли человеческой точности распознавания лиц.
Живой грим (искусство)
Зимой 2016 года на 58-й ежегодной церемонии вручения наград «Грэмми» Леди Гага исполнила трибьют умершему незадолго до того Дэвиду Боуи. Во время выступления по ее лицу растеклась живая лава, оставив на лбу и щеке узнаваемый всеми поклонниками Боуи знак — оранжевую молнию. Эффект движущегося грима создавала видеопроекция: компьютер отслеживал движения певицы в режиме реального времени и проецировал на лицо картины, учитывая его форму и положение. В Сети легко найти видеоролик, на котором заметно, что проекция еще несовершенна и при резких движениях слегка запаздывает.

Технологию видеомаппинга лиц Omote Нобумичи Асаи развивает с 2014 года и уже с 2015-го активно демонстрирует по всему миру, собрав приличный список наград. Основанная им компания WOW Inc. стала партнером Intel и получила хороший стимул для развития, а сотрудничество с Ишикавой Ватанабе из Токийского университета позволило ускорить проекцию. Впрочем, основное происходит в компьютере, и похожие решения используют многие разработчики приложений, позволяющих накладывать на лицо маски, будь то шлем солдата Империи или грим «под Дэвида Боуи».
Александр Ханин, основатель и генеральный директор VisionLabs

«Подобной системе не нужен мощный компьютер, наложение масок может производиться даже на мобильных устройствах. Система способна работать прямо на смартфоне, без отправки данных в облако или на сервер».
«Эта задача называется трекингом точек на лице. Есть много подобных решений и в открытом доступе, но профессиональные проекты отличаются скоростью и фотореалистичностью, — рассказал нам глава компании VisionLabs Александр Ханин. — Самое сложное при этом состоит в определении положения точек с учетом мимики и индивидуальной формы лица или в экстремальных условиях: при сильных поворотах головы, недостаточной освещенности и большой засветке». Чтобы научить систему находить точки, нейронную сеть обучают — сначала вручную, скрупулезно размечая фотографию за фотографией. «На входе это картинка, а на выходе — размеченный набор точек, — поясняет Александр. — Дальше уже запускается детектор, определяется лицо, строится его трехмерная модель, на которую накладывается маска. Нанесение маркеров осуществляется на каждый кадр потока в режиме реального времени».

Примерно так и работает изобретение Нобумичи Асаи. Предварительно японский инженер сканирует головы своих моделей, получая точные трехмерные прототипы и готовя видеоряд с учетом формы лица. Задачу облегчают и небольшие маркеры-отражатели, которые клеят на исполнителя перед выходом на сцену. Пять инфракрасных камер следят за их движениями, передавая данные трекинга на компьютер. Дальше все происходит так, как нам рассказали в VisionLabs: лицо детектируется, строится трехмерная модель, и в дело вступает проектор Ишикавы Ватанабе.
Устройство DynaFlash было представлено им в 2015 году: это высокоскоростной проектор, способный отслеживать и компенсировать движения плоскости, на которой отображается картинка. Экран можно наклонить, но изображение не исказится и будет транслироваться с частотой до тысячи 8-битных кадров в секунду: запаздывание не превышает незаметных глазу трех миллисекунд. Для Асаи такой проектор оказался находкой, живой грим стал работать действительно в режиме реального времени. На ролике, записанном в 2017 году для популярного в Японии дуэта Inori, отставания уже совсем не видно. Лица танцовщиц превращаются то в живые черепа, то в плачущие маски. Это смотрится свежо и привлекает внимание — но технология уже быстро входит в моду. Скоро бабочка, севшая на щеку ведущей прогноза погоды, или исполнители, каждый раз на сцене меняющие внешность, наверняка станут самым обычным делом.

Фейс-хакинг (активизм)
Механика учит, что каждое действие создает противодействие, и быстрое развитие систем наблюдения и идентификации личности не исключение. Сегодня нейросети позволяют сопоставить случайную смазанную фотографию с улицы со снимками, загруженными в аккаунты социальных сетей и за секунды выяснить личность прохожего. В то же время художники, активисты и специалисты по машинному зрению создают средства, способные вернуть людям приватность, личное пространство, которое сокращается с такой головокружительной скоростью.
Помешать идентификации можно на разных этапах работы алгоритмов. Как правило, атакам подвергаются первые шаги процесса распознавания — обнаружение фигур и лиц на изображении. Как военный камуфляж обманывает наше зрение, скрывая объект, нарушая его геометрические пропорции и силуэт, так и машинное зрение стараются запутать цветными контрастными пятнами, которые искажают важные для него параметры: овал лица, расположение глаз, рта

Розовые и фиолетовые, желтые и синие тона доминируют в линейке одежды HyperFace, первые образцы которой дизайнер Адам Харви и стартап Hyphen Labs представили в январе 2017 года. Пиксельные паттерны предоставляют машинному зрению идеальную — с ее точки зрения — картинку человеческого лица, на которую компьютер ловится, как на ложную цель. Несколько месяцев спустя московский программист Григорий Бакунов и его коллеги даже разработали специальное приложение, которое генерирует варианты макияжа, мешающего работе систем идентификации. И хотя авторы, подумав, решили не выкладывать программу в открытый доступ, тот же Адам Харви предлагает несколько готовых вариантов.

Человек в маске или со странным гримом на лице, может, и будет незаметен для компьютерных систем, но другие люди наверняка обратят на него внимание. Однако появляются способы сделать и наоборот. Ведь с точки зрения нейросети изображение не содержит образов в обычном для нас понимании; для нее картинка — это набор чисел и коэффициентов. Поэтому совершенно различные предметы могут выглядеть для нее чем-то вполне сходным. Зная эти нюансы работы ИИ, можно вести более тонкую атаку и подправлять изображение лишь слегка — так, что человеку перемены будут почти незаметны, зато машинное зрение обманется полностью. В ноябре 2017 года исследователи показали, как небольшие изменения в окраске черепахи или бейсбольного мяча заставляют систему Google InceptionV3 уверенно видеть вместо них ружье или чашку эспрессо. А Махмуд Шариф и его коллеги из Университета Карнеги — Меллон спроектировали пятнистый узор для оправы очков: на восприятие лица окружающими он почти не влияет, а вот компьютерная идентификация средствами Face++ уверенно путает его с лицом человека, «под которого» спроектирован паттерн на оправе.